Model-Based Machine Learning
• admin@sciloo.com
ML not equal to data + black box
ML = data + assumptions
Free Lunch Theorem
As per free lunch theorem, without assumptions we can’t build anything. We can’t have one generic
We have constraints like
assumptions,
prior knowledge,
domain knowledge
when dealing with problems and without considering these how we can solve a problem.
Data + prior knowledge
Detection of a person in frame
In a simple approach, we will need many images with person at different location.
But with this knowledge, we can develop transformations to shift a person in the image and then train the model on these images instead of acquiring those images.
We tend to think about Big data that we can develop weak models and can forget the constraints/assumptions.
There are 2 types of sizes
1. computation size
2. statistical size
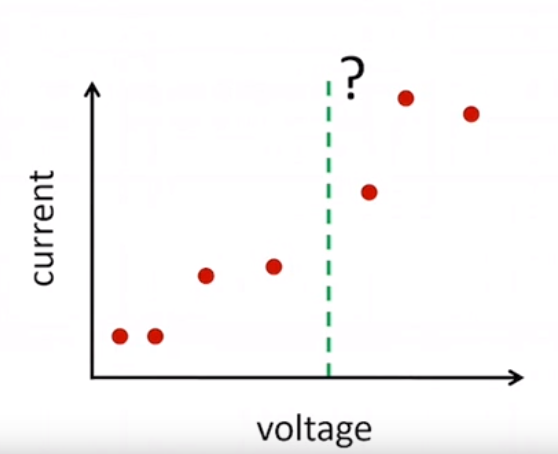
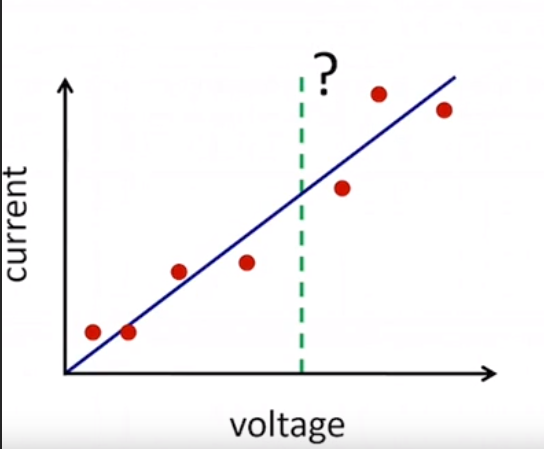
Computationally small but statistical big
Without assumptions, how we can predict a current value for a new voltage value? On the right side, we can take into consideration about V = IR and can be confident that the line is good predictor for future voltage values. This dataset is small in computational size but big in statistical size.
 </figure>
</figure>
Statistically small but computationally big
The above data is computationally big, take a simple example of a
Unless we make assumptions, it is very difficult to do computation with these big set of images. This above images data can be computationally very large but statistically very small.
Model based ML
Instead of getting lost in the sea of algorithms/models/research papers, we should use model-based learning to use data and assumptions to derive ML algorithm. We should work mainly on defining our assumptions about the problem very clearly.
</figure>
Translate your assumptions into a model and that is the core of model-based learning. If our assumptions are sound/strong then we get much more information from the same amount of data.
Can we develop a tool to do it automatically? Can this dream be true?
 </figure>
</figure>
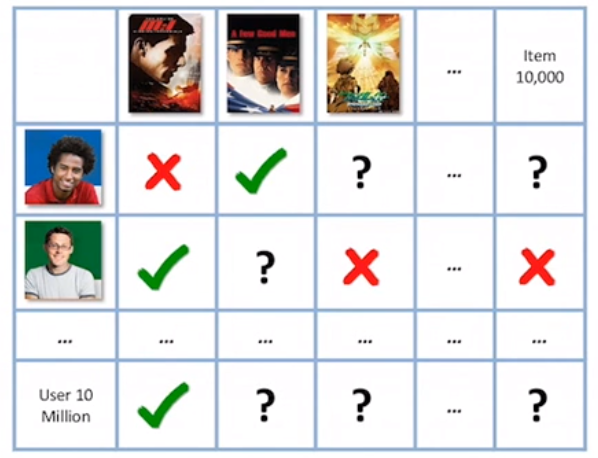
User & Movies
Predict the question marks – whether a user like or dislike those movie for which he has not given a answer. 10ks of movies, 10Ms of users.
 </figure>
</figure> 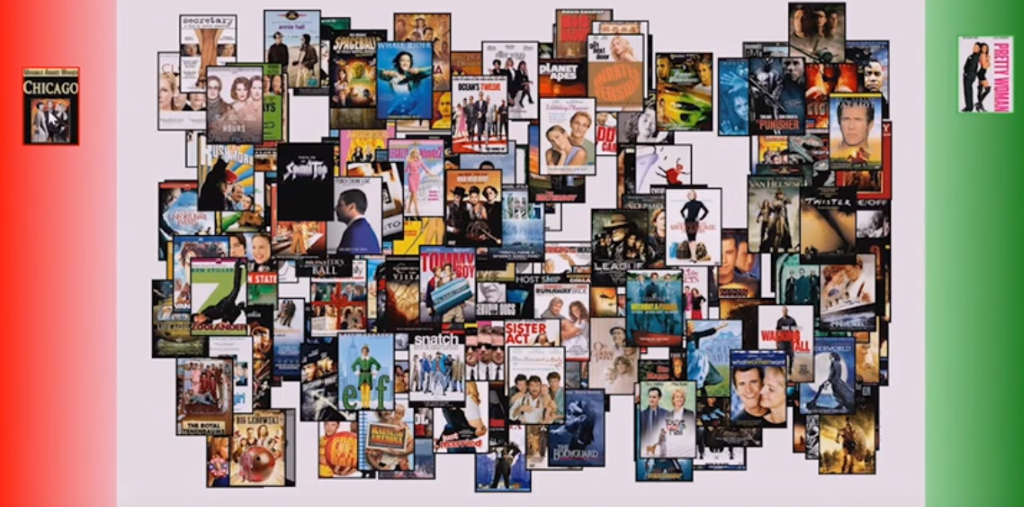
Based on my like or dislike, ML is suggesting movies closer to green area that I can like for sure and closer to red area for movies that I may not like.
It is learning my behavior and suggesting me titles based on the populations similar to me.
Information (as per information theory by Shanon) is the surprise from data. Just like above movie ML algo suggest me movies closer to green area and I pick then there is a very less surprise in the data and suggestions don’t move big.
But instead of liking the movie, if I dislike it, it is a big surprise for the algo and movies suggestions move big.
Quantifying uncertainty
Uncertainty is an essential part of machine learning and it is a modern view of ML. Bayes theorem is at the core of it.
BT: P(A/B) = [P(A) * P(B/A)]/P(B)
Bishop view on Healthcare
</figure>
It is one of the biggest opportunities but complex also. Personalized healthcare can be a phenomenon suggesting you personalized course of treatment because as an individual each one of us is unique. It is like machine can learn our movies preferences.
This can happen by analyzing the info from other millions of people.
Cloud based tech + ML tech + Domain experts (from Hospitals like clinicians, doctors, radiologists, etc.)
Trust and privacy in the Data
Data is encrypted so it is only accessible to those who have keys but It can become vulnerable while being processed. So Microsoft has taken care of processing data in
Factor Graph
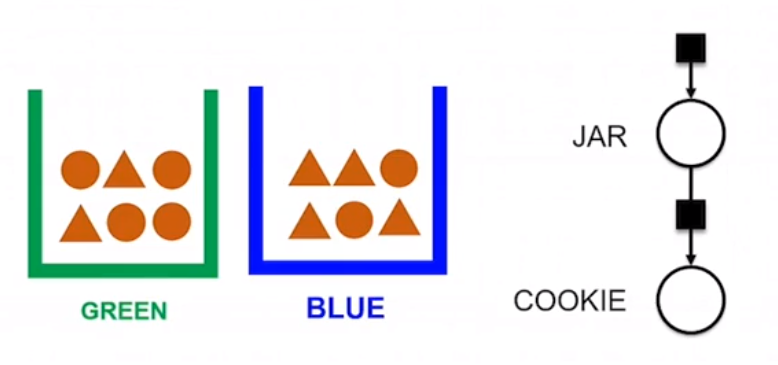 </figure>
</figure>
The probability of getting a circular or triangular cookie depends upon which jar we choose. Round circles on the right sides are – one random variable for Jar, one random variable for Cookie
These random variables are driven by their respective probability distribution functions (PDFs) denoted as shaded squares.